Thanks for deep answer
Yap, it seems there is difference in set gpu clock in one step or in 2 steps (gui + after cli)
I’ll test 1080MHz in gui vs -500 gui at boot and 750 cli
or… eg -500 gui and after 1080MHz in gui too
Thanks a lot


Thanks for deep answer
Yap, it seems there is difference in set gpu clock in one step or in 2 steps (gui + after cli)
I’ll test 1080MHz in gui vs -500 gui at boot and 750 cli
or… eg -500 gui and after 1080MHz in gui too
Thanks a lot
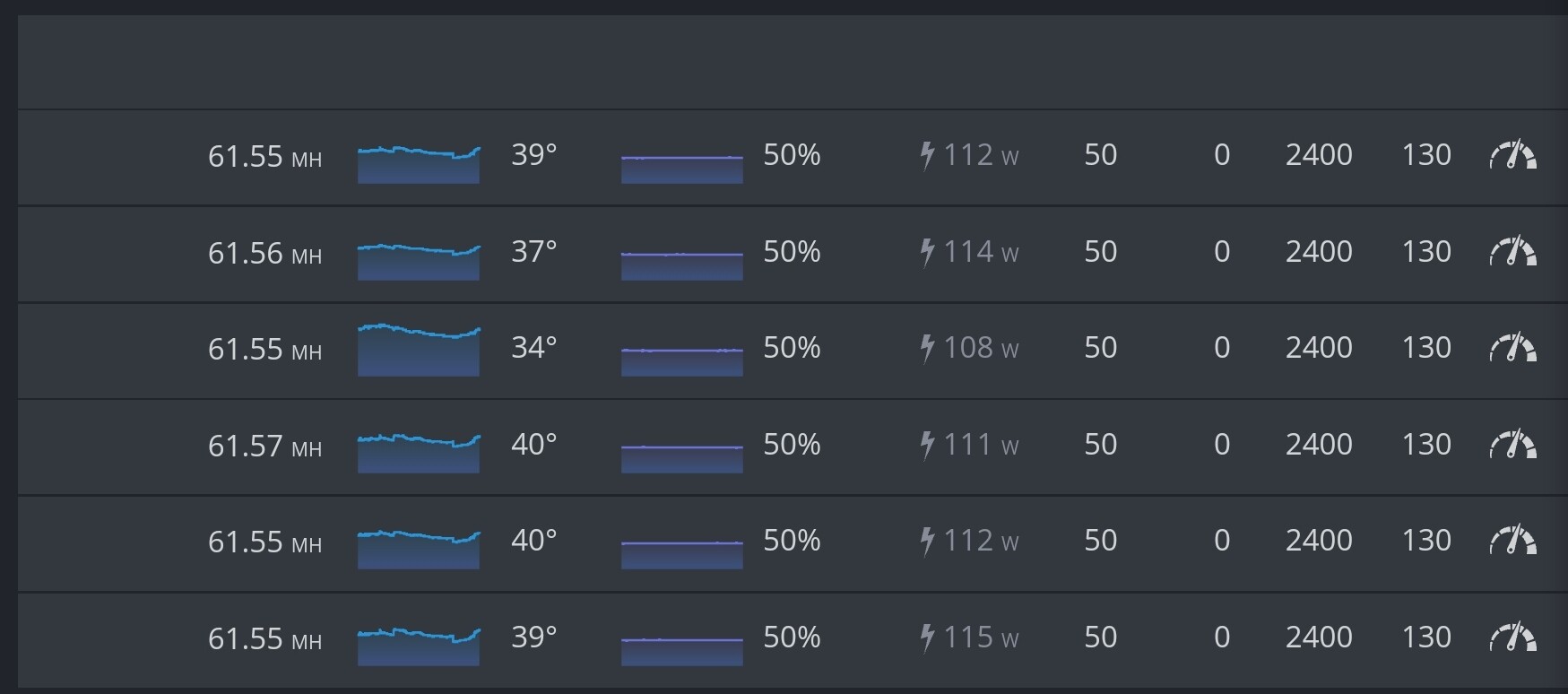
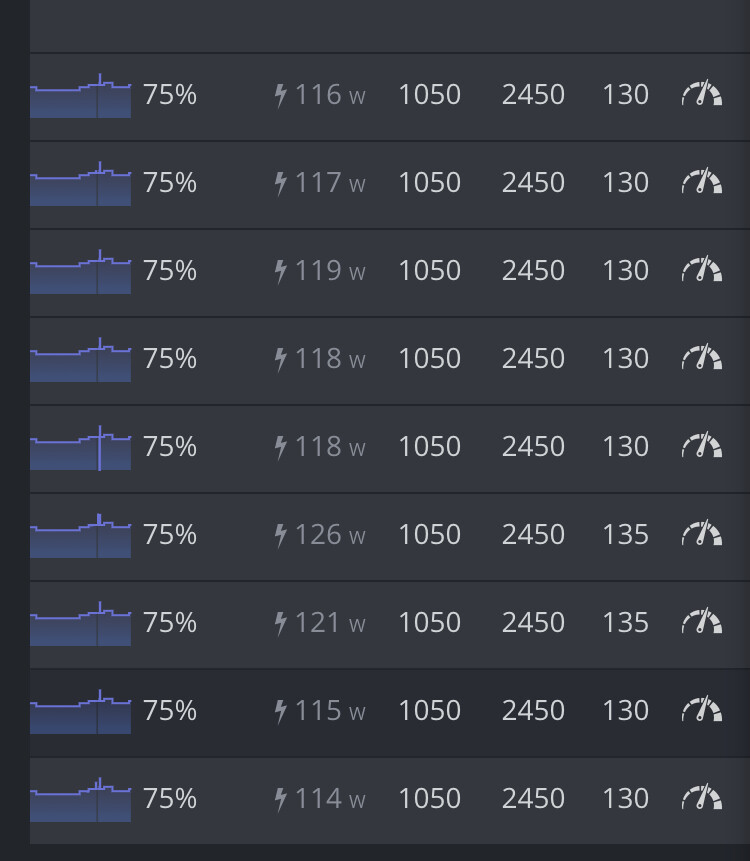
In my quick try… (4xRTX3070)
PL: 130
Time waiting for stabilize ~> 1h
It’s seems it’s repeatable
any tips for Asus TUF OC 3080?
Thanks in advance
Good thing you don’t have to use sudo in the Hive console
Hope this ‘‘secret’’ config file will come in handy. You can create a skeleton version by executing
echo 'DEF_FIXCLOCK=-200' > /hive-config/busid.conf
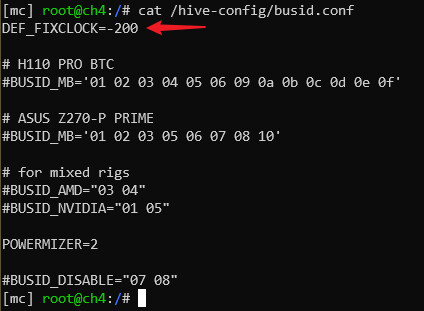
and then forget about lgc thing for good
Could you please elaborate on this a little?
Tried -200 and -400, but didn’t notice any effect.
Google knows nothing about this.
You should apply OC from the Hive dashboard or run nvidia-oc from the console. Then examine the output of nvidia-oc
Thank you! It works! Very much appreciated.
BTW seems that I can set only the same value for all cards. Is it possible to set different value for each card that way? Tried comma and space separated list, but no luck.
UPD: Nevermind. Figured it out. Had to modify nvidia-oc script a bit. Now it accepts array of values in DEF_FIXCLOCK.
I did not understand anything ? a little more explanation, I put my values ditto and I see no change …
That file I mentioned before is a configuration file for nvidia-oс script. You should run nvidia-oс right after the updating
Could you please share you configs for the 2060 @SnowmanSimon ? How much on the cli and how much on the GUI?
Thanks man
After more than 50 days of trial , jumping from windows to hiveos
I was thinking that I found the right OC for my 9x RTX 3070
I use AsRock H110BTC
2x Corsair 1200W platinum
Riser feed via 6pin …etc
T-rex miner.
All works well with no rejected shares
but the miner decides to restart after ~6h (max managed of 17h)
When I check the logs in shell tells my CUDA ERROR…lower oc … which I did… I left them at 1070 which worked for 14h, no issues after that… miner restart again.
Now I will trial the ss below …
What am I doing wrong…?
clock 1070
memory 2400
pl 130
Stable no problem
Hi all,
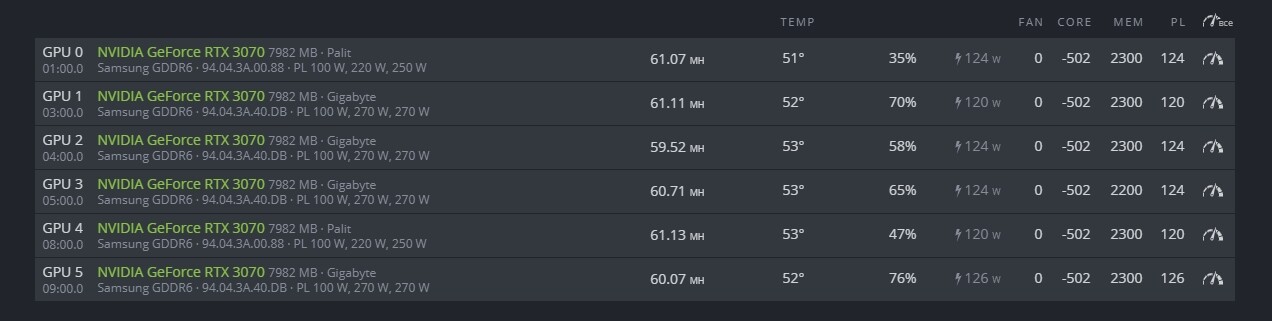
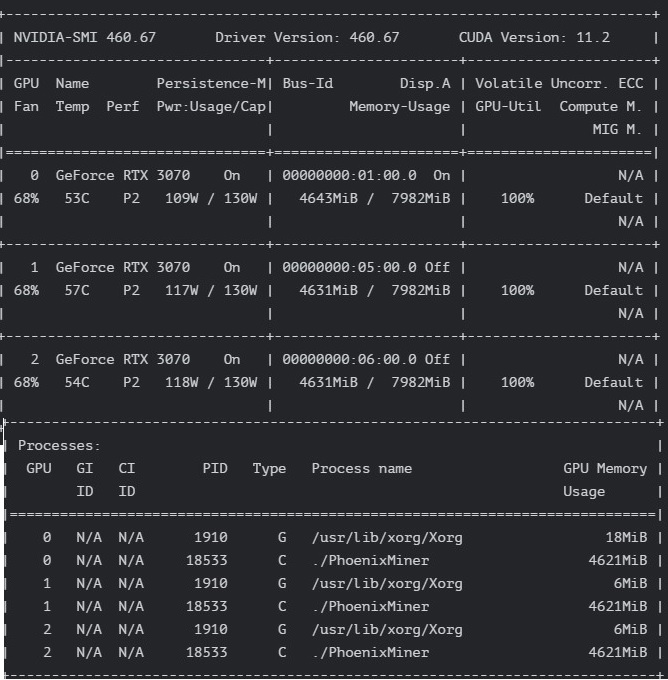
I am wondering if there is anything wrong with the card, any thoughts? On the picture I see that Disp.A is on “ON” and /usr/lib/xorg/Xorg is at 18MiB versus others cards at 6MiB.
Anyone would know if that is a good thing or is there something I could do to bring back the card how it was before I used the lgc command?
locking the core speed… doesnt it mean that you have locked it to 670 megahertz? but you use for the cards absolute core clock 1070 … so you locked it too low. Just remove the locking and use absolute core clock, it works better with absolute.
Also Display A i guess it means you have connected the monitor to this GPU?
Thanks for your reply,
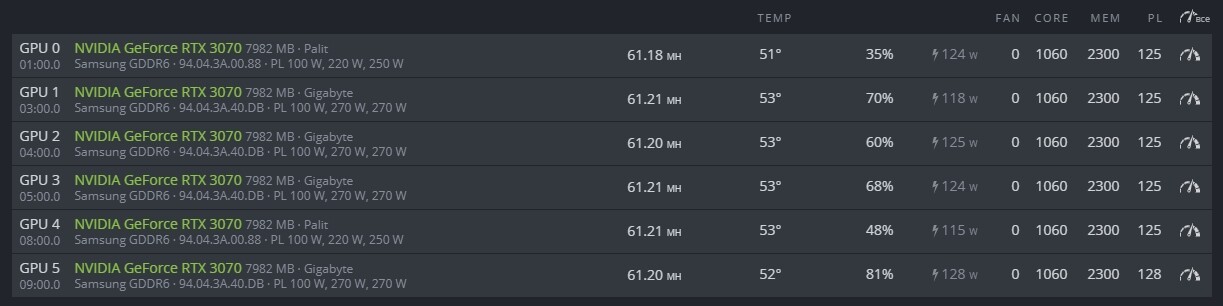
I have put them back on 1070, now trying 1080MHz (see picture) but the GPU 0 still is at 109W with the above info mentioned in my previous post.
I also thought that Disp.A may be the monitor thing. I have connected it once to set up the BIOS and then removed but it seems it may have stayed as is.
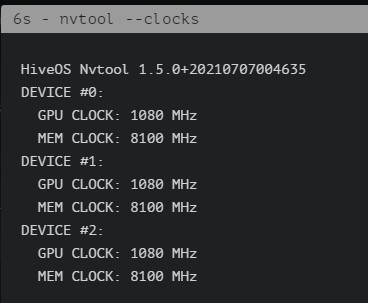
See the picture, my clocks are back to 1080 but I still have few more invalids on that GPU 0 and the /usr/lib/xorg/Xorg is still at 18MiB.
I have tried the following commands but the card still runs at 109W (maybe it’s a good thing, though I am getting more invalids than I used to have)
nvidia-smi --reset-gpu-clocks
do you want to try switch places of the GPU with another? that might disrupt the good working of the other also but it could fix problem also.
I’ll try to have it run few more hours and if that is still not changing I will try to move the gpus around and see if that does something or not.
Though what I am “worried” about is that I used to have my reported hashrate (from the miner) vs. average effective hashrate (from the pool) very close (e.g. reported 187MH for effective 183MH), now I have reported 187MH for effective 170MH which is much worse). Maybe it only depends on the luck of the pool on that day but I wonder (still new to this so…), using flexpool as of now.
Also, when the miner/os resets for any reason is there a way to execute the nvidia-smi -lgc command automatically? else it will simply mine with an offset core clock at 130W (PL limit I have set up) until I rewrite the command. If not possible, it might be better to go with the GUI absolute clock just in case.