



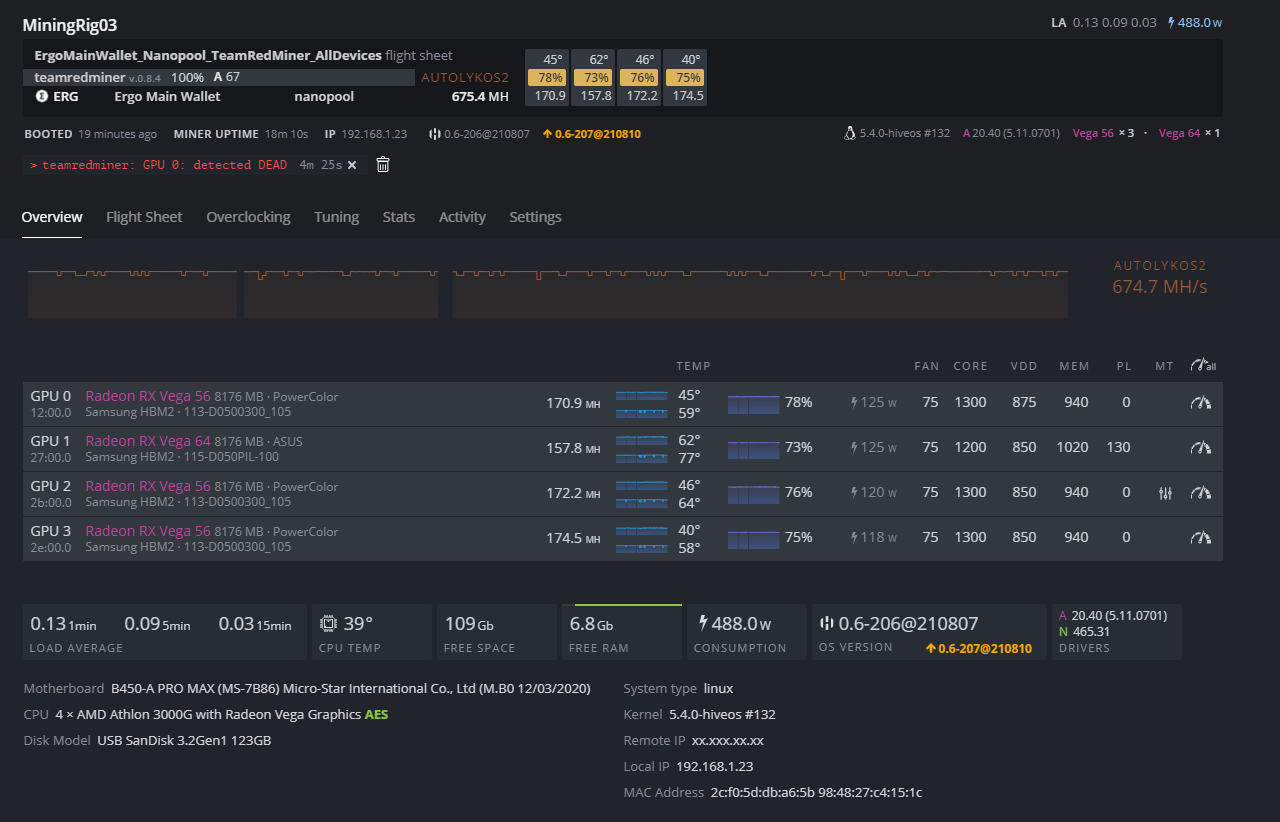
Hi All, I am a new crypto miner and recent lurker on this forum. Glad to join and hopefully be able to contribute to others. I have a rig of 1 x vega 56 and 3 x vega 64 mining Ergo. I am getting good hash rate and efficiency with TRD but I am hating the regular " GPU 0: detected DEAD (12:00.0), will execute restart script watchdog.sh" error. Sometimes it reboots fine and resumes but other times it gets stuck on reboot and I need to manually shutdown and start up, which is not sustainable. GPU 0 and GPU 3 are vega 64s that are flashed as 56. Any ideas?
- not enough voltage ==> adjust VDD by 12mV step
- memory failure occurred ==> reduce memclk by 5MHz step
It is like one of them and possible both cases.
For all cards or only the GPU that the error is referencing, GPU 0 in this case?
Sure, that only for GPU which was involved issues
Got it. I upped GPU 0 by 12mv and will monitor for now. If the error happens again, I will decrease mem by 5 MHz as you suggested.
Update: I thought issue was resolved after increasing VDD by 12mV as it was stable for 32+ hours. Woke up this morning to see it had rebooted twice, first time 10 hours ago, and another time 9 hours ago due to GPU 0 detected dead. I increased VDD by 13mv to 900mv. If it happens again, I will begin reducing the mem OC.
How do I know if if the error emerge because of mem or power?
I don’t think you can know without testing. That’s why I am focusing on power first and if that doesn’t help, I will try the memory. It’s interesting though that I have the exact same card and no issues at same VDD and mem OC. Fun times.
To bad that it isn’t visible….
Every card is different, I hope you will find the right settings!
1 Like
GPU dead had been a big pain in the head to me.
The fixing i got was changing my psu cable. I realized there was a slight melt on the other end.
lots of reasons for a dead gpu.
- Too high overclocks. or Too high O/C but straps aren’t supporting them.
for your case your rig runs lower than my 195-200 m/hash range. So i’m thinking its not the case. - Faulty riser/s.
- Not enough power juice from a PSU. As a rule only use 80-85% wattage from your PSU.
Oh man. I am about to rip my hairs out lol. It keeps getting weirder. I no longer get GPU0 detected dead after increasing VDD to 900mV and increasing (counterintuitive, I know) mem OC to 960 and applying straps but I started to get GPU2 detected dead around 30 hours or so into mining. Rig would restart automatically and not detect GPU2 at all. Turns out that’s being caused by a loose 8 pin connection at GPU2. Fixed that and now I am getting GPU2 detected dead about every 12 hours but when it restarts at least it detects GPU2 and gets back to mining fairly quickly. I’ve increased VDD on GPU2 (Vega 56 Red Devil) to 862mV from 850mV to see if that helps.

So, I have good news! Rig has been mining for 4 days without any issues. I ended up replacing the 8pin power cable from PSU to GPU2. Thanks to @akosi & @HaloGenius for helping this sort this out!!
For new folks running into the “GPU detected dead” error, I recommend the following:
- Increase VDD by 12mV for GPU causing error and keep track at how frequently error is popping up
- If no change in frequency of error, reduce mem OC by 5MHz
- If no change in error frequency or you see error popping up at random intervals, most likely it’s a power delivery issue(riser, power to riser, power to GPU, PSU) to that GPU. As soon as error happens, check the GPU to see if it has power. In my case, I saw the LED light was off after rig rebooted and discovered one of the 8-pin cables was shot.
- If no power delivery issue detected, go back to step 1 and adjust VDD then step 2 until your rig is stable.

glad it worked well for you. If you’re comfortable scratching your head again to bump 20 mhash more.
try these O/C
Straps:
amdmemtweak --CL 20 --RC 37 --RP 11 --WR 14 --CWL 8 --FAW 12 --RAS 20 --REF 65535 --RFC 248 --RRDL 6 --RRDS 3 --WTRL 9 --WTRS 4 --RCDRD 12 --RCDWR 12
Overclock is in the picture. It will add 20-30W more. But may cause instability until you find the right mix and match with VDD and Memory.

20 mhash per card would be awesome. I’ll delve into this once I have some free time to tweak and monitor. Thanks for sharing your straps and OCs. I am noticing your ASUS cards run muuch cooler than mine. I wonder if I should replace thermal pads. Mine has mem at 74C with only 125W and ambient temperature is 22C. The PowerColor Red Devils have great cooling.
they are stock thermal pads and one of them is Asus Strix Arez. I re-applied a thermal paste once every 6-8 months.
Lower your memory to 930, autolykos is more of a core intensive compared to eth which you have to ramp the memory.
Wow! I was able to get another 64MH/s out of my 4 cards. I had to flash my ASUS Vega 64 as Vega 56 to make it stable. After that I applied your straps, lowered mem clock, and increased core clock while tweaking VDD if it crashed. It’s has been running for 15 hours, no issues. I was able to push my ASUS card to 195MH/s but the temps started getting too high, so I dialed it down a bit. Thanks so much for the advice and encouragement to get better performance!
*Note: 5600XT is on ETH

This topic was automatically closed 416 days after the last reply. New replies are no longer allowed.