



I think ethash vardiff retarget timer is set too low and variance too high in pool config. It changes too often and some higher diff. shares are wasted due to this because it retargets to lower difficulty too soon Here the example:

In the example above, you see the rig generates 2500MH shares no problem for a while, like every 5-10 seconds. Then the rig is out of luck for 50 seconds, which triggers the diff. set to 1250MH, but this is followed by 3 found shares in the next second with difficulty above 2500MH. But they are now only 1250MH shares, which is a waste. If the server would wait another 30 seconds for diff. change, the shares would still be 2500MH, and the difficulty would stay 2500MH because of submitted shares.
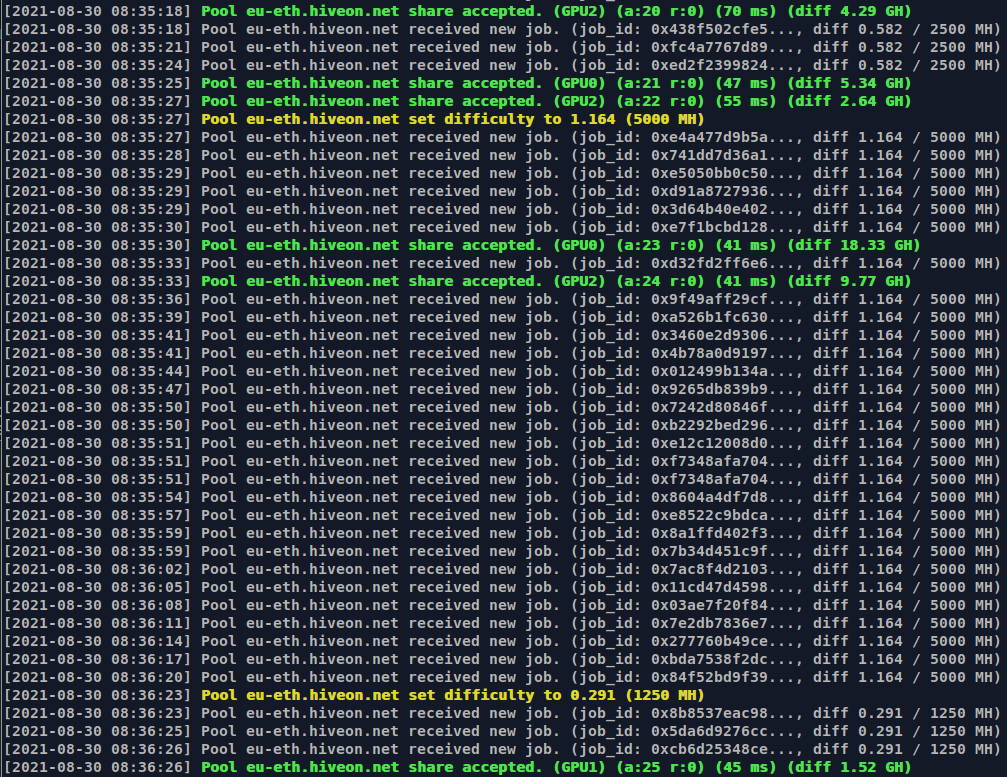
In the next example you see difficulty being switched from 5000 to 1250MH. Why in the god’s name would you do that??
These issues could be solved by either:
-
Having more difficulties (not just 100% increments like 1250, 2500, 5000, 10000, etc., but something in between, say 1250, 1500, 1750, 2000, 2250, 2500, etc.).
-
Increasing retarget time interval to say 120 seconds, or even 180 seconds.
-
Providing some stratum ports with vardiff not going under certain threshold, say minimum of 2500MH, or 5000MH.
But I vote for solution 1. or 2. or both 1 and 2 would be even better.