Problem:
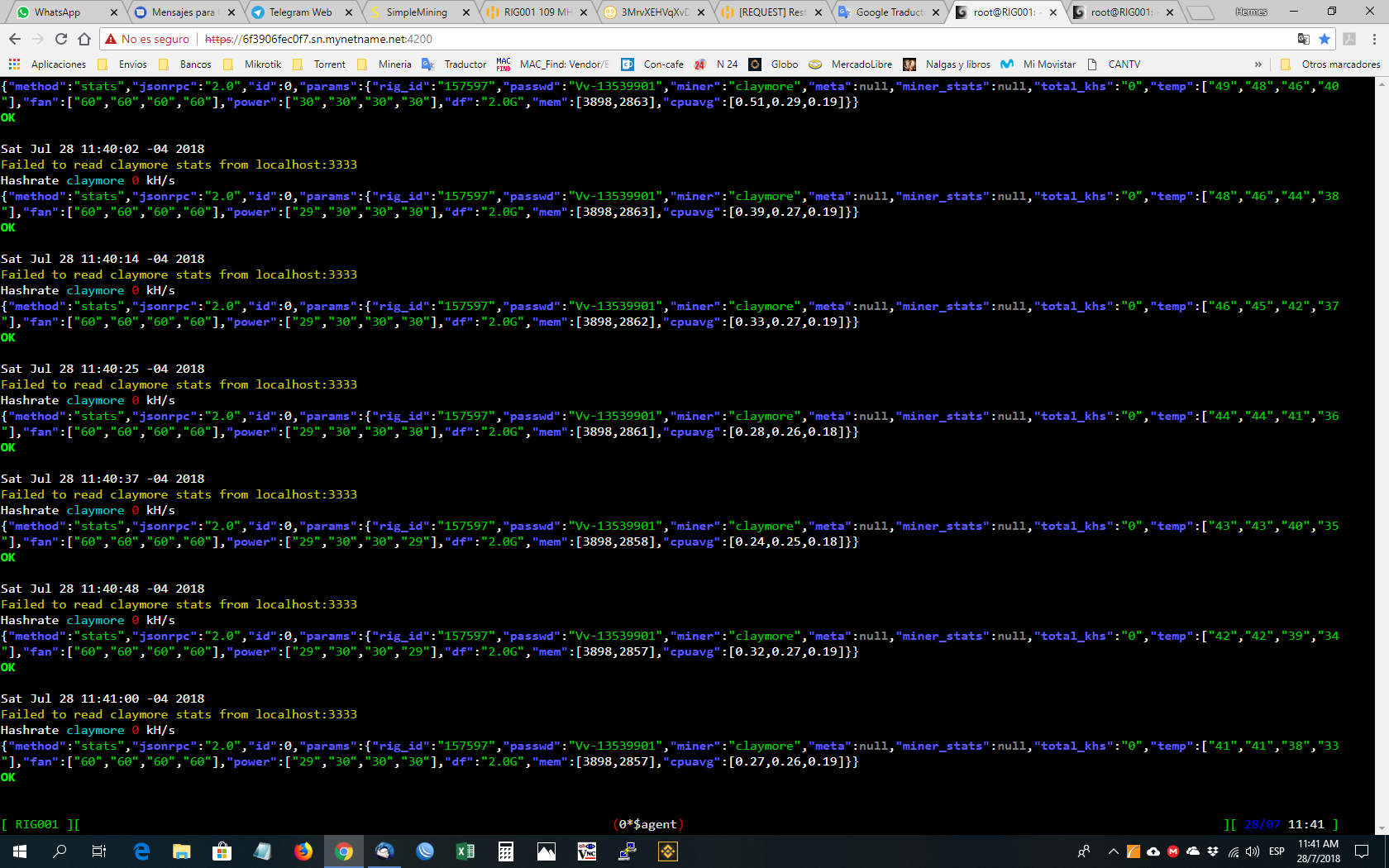
Roughly, every 100 hours Hive Agent can’t read stats from Claymore monitoring port. As a result, rig is online in Hive Dashboard, but miner is presented offline even though it is working just fine.
Situation can be confirmed with lots of connections in “CLOSE_WAIT” status and their number is growing with Agent’s every new attempt to read data from Claymore (10 secs by default).
Situation is rectified by manually restarting miner.
Solution:
Event though I believe this is miner problem, there is an easy workaround that can be implemented in /hive/bin/agent.miner_stats.sh by adding one (or two) lines of code:
if [[ $? -ne 0 || -z $stats ]]; then
echo -e "${YELLOW}Failed to read $miner stats from localhost:3333${NOCOLOR}"
#Start of new code to be added ==========
netstat -anp | grep ':3333 ’ | grep CLOSE_WAIT | awk ‘{print $7}’ | cut -d / -f1 | grep -oE “[[:digit:]]{1,}” | xargs kill
sleep 5
#End of new code to be added ==========
else
As it can be seen, when this situation occurs, instead of just writing info message in Agent’s screen, we can additionally drop all problematic connections. That basically kills miner process which is then restarted by default.
It would be really helpful to implement this in HiveOS since every update is overwriting existing script.