



Seems maybe PL did not fix it, this problem came back today. Other posts indicate it is some sort of problem with the nVidia driver and interrupts, etc. Hopefully someone from Hive can chime in.
The OhGodAnETHlargementPill option was discovered today in the Nvidia OC setup.
I wonder if anyone can briefly mention what the main function is.
The current test setting parameter is MEM 1600 FAN 90 PL 85.
There is a sense that using this setting parameter is not bad.
Try to apply this value to other machines for observation.
Continuous observation
P.S: This is a GOOGLE translation. If you feel strange grammar, please forgive me.
A problem has recently occurred. Some problems may arise on some machines.
On the 12-card machine, there is a condition where the fan of the graphics card is displayed as Fan = 0%.
The following error message appears when using gpu-fans-find
ERROR: Error assigning value 0 to attribute ‘GPUTargetFanSpeed’
(jga012:0[fan:8]) as specified in assignment
‘[fan:8]/GPUTargetFanSpeed=0’ (Unknown Error).
ERROR: Error resolving target specification ‘fan:11’ (No targets match target
Specification), specified in assignment ‘[fan:11]/GPUTargetFanSpeed=0’.
However, during the actual observation of the operation of the machine, it was found that all the display card fans are in continuous operation.
Is it when I stop the miner and enter the gpu-fans-find command
Should all fans stop completely?
I found that when I enter the gpu-fans-find command, 1 to 2 of the graphics card fans will still run
Trying to catch the problem…
Enter gpu-fans-find
Reopen the miners after some time
appear
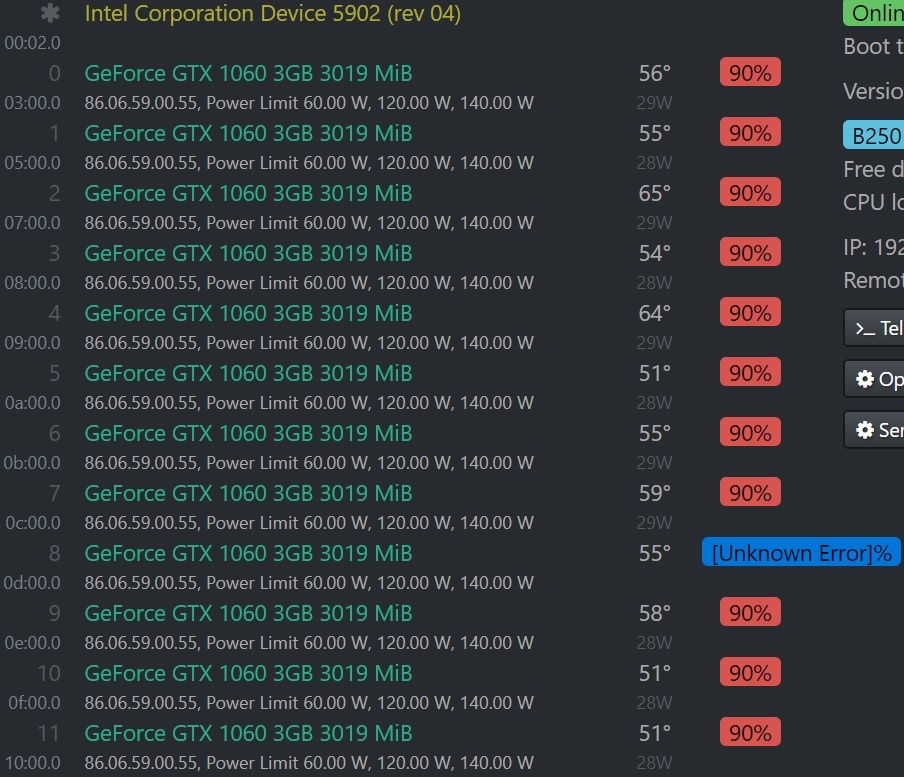
Thinking about debugging:(
OhGodAnETHlargementPill 這個選項是提供給 1080TI 使用的,能提高算力到 50 多一些。對於 1063 並沒有用處。
至於 1063 的調試值,我的數值如圖示,算力大約在 24.xx 穩定。但是要看你 1063 的記憶體顆粒品牌,通常三星顆粒才有 24 的效能,美光大約在 22~23 左右。
而且 Hive OS 對於單卡的設定很敏感,我在 Win10 上能穩定跑的設定,在 Hive OS 上必須要針對單卡微調設定才會穩定,但是這個作法同時提供給我很好的算力結果。
提供給你參考

[quote=“oceanwang;3251”]OhGodAnETHlargementPill 這個選項是提供給 1080TI 使用的,能提高算力到 50 多一些。對於 1063 並沒有用處。
至於 1063 的調試值,我的數值如圖示,算力大約在 24.xx 穩定。但是要看你 1063 的記憶體顆粒品牌,通常三星顆粒才有 24 的效能,美光大約在 22~23 左右。
而且 Hive OS 對於單卡的設定很敏感,我在 Win10 上能穩定跑的設定,在 Hive OS 上必須要針對單卡微調設定才會穩定,但是這個作法同時提供給我很好的算力結果。
提供給你參考
http://forum.hiveos.farm/uploads/editor/h9/99rewvag2x3j.png[/quote]
這真是太感謝了!!
我的少數機器中偶爾會出現
Claymore Reboot: WATCHDOG: GPU error, you need to restart miner 
這個訊息
看來我必須單獨的一張一張去設置超頻參數才能夠讓我的機器更穩定的運作
另外,關於OhGodAnETHlargementPill這個選項
我有台1066非常的怪,不開這個選項他彈出GPU錯誤訊息重開的機率相當之高
但是我勾了這個選項開啟之後頻率下降了?
(從一天十幾次降到個位數)
呃…這不知道是我的心理因素還是一種出乎意料之外的狀況
也許是剛好在這段時間他跑得比較穩定?囧?
這幾天都一直在觀察機器的運作狀況
另外我想跟您請問
你最下列咖啡色的WD跟claymore是代表什麼數值設定呢?
我並沒有在我的HIVEOS找到類似的選項?
(也可能是我還沒有更深的摸透這個系統的使用)
另外關於顆粒的部分
呃,我當初在WIN系統上作業的時候我是有去記我的顯卡顆粒
但轉HIVEOS之後我整個都忘記=_=
我只記得我三星,海力士,美光這三種的顯卡都有
(等等,這麼一說我整個有點混亂,因為我1063.1066.1070.1070ti.這幾種卡片我都有用到= =!!)
而目前我1063部分的設定,我大多平均都讓一台跑到285~295之間(12卡)
所以平均下來我一台卡差不多都是24左右
在此忽然發現,這或許是我常常出現Claymore Reboot: WATCHDOG: GPU error, you need to restart miner 錯誤的原因,或許一方面是我沒有做好單卡的超頻微調,一方面是我沒注意到顆粒的部分讓他超頻過頭了
您的回覆真是讓我一語驚醒夢中人
看來我必須要再次的一台一台的調適我的機器
(這感覺起來會是個讓人無從著手的大工程)
無論如何,非常非常的感謝oceanwang!!
我試著把所有的參數從
MEM 1500
FAN 90
PL 85
這種統一的參數設定
分開變成
MEM 1500 1500 1500 1500 1450 1500 1500 1500 1450 1500 1500 1500
FAN 90 90 90 90 90 90 90 90 90 90 90 90
PL 85 85 85 85 88 85 85 85 88 85 85 85
其中一台機器設定是這樣
結果我常常出現的問題解決了
本來Hive OS 控制介面會出現

(上圖為其他台還沒設定的問題機器)
單獨分開設定之後變成

(這張圖是我常出現問題的機器做設定之後的現況)
這真是太好了
CPU LOAD 105%!!
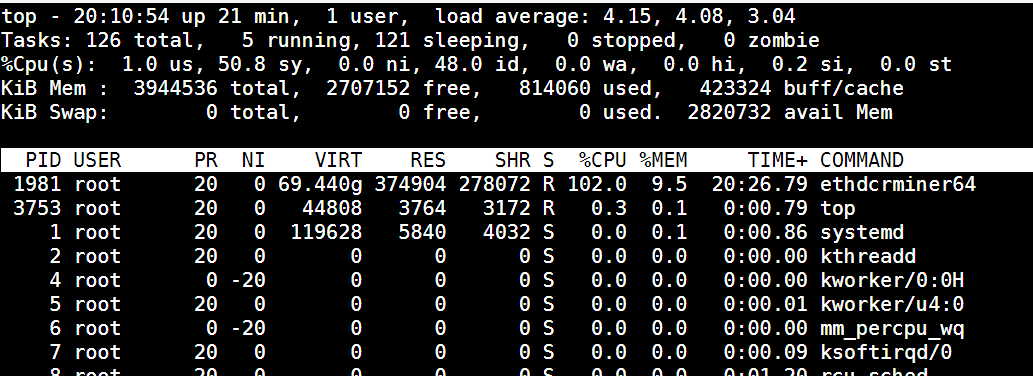
что интересно с 3 1050ti все нормально. стоит добавить 1060 3гб
[quote=“Mishka;3312”]CPU LOAD 105%!!
что интересно с 3 1050ti все нормально. стоит добавить 1060 3гб[/quote]
I try to increase my PL value.
This was helpful at the time to stabilize my machine.
(includes CPU load avg)
At the moment I am still observing whether my settings are more stable.
Do you want to try to increase the PL value first?
P.S: This is a GOOGLE translation. If you feel strange grammar, please forgive me.
P.S 2: My GOOGLE TRANSLATOR has no way to translate your text so that I can understand what it really means. I can only make guesses. I am sorry if I understand it wrong.
thank you. i will try to increase power limit.
I will report the results.
but separately 1050 work perfectly without glitches
power limit usually 75 for 1060 and 60 for 1050ti.
but in this case 85 and 70.
problem is not gone.
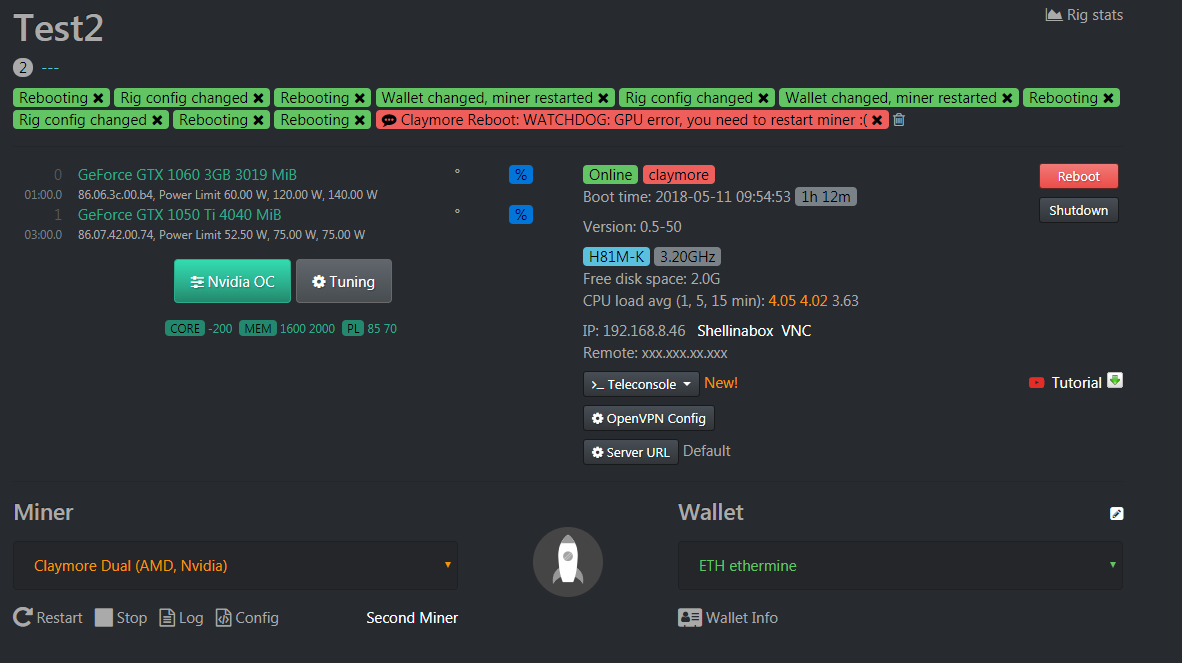
I had this issue and i switched in the Bios of my Motherboard (H81 PRO BTC R2.0) from Gen1 to Gen2. This fixed the high CPU usage.
you could also check the cpu load in the terminal with the command “htop” does claymore really is the problem thread?
I have encountered some problems these days to share.
For example, as the temperature begins to heat (I have already entered the summer here), the operating temperature of the machine begins to rise.
When the operating temperature reaches more than 75 degrees Celsius, the Claymore program that looks like HiveOS will begin to manage its work efficiency.
The average amount of power will decrease by about 20 to 40% depending on the temperature.
The 12-card can run to a value of 280 to 290 on average, and will drop to 220 to 240 after the temperature is too high to start controlling.
It is sometimes reduced to around 200.
This is a troublesome issue. (But the weather is regarded as a force majeure, and you can only think of ways to do the deployment)
It is planned that the relocation of the equipment room will be carried out in May-June. In the heat dissipation part, it will continue to observe whether there is a better solution.
In this part, probably because of the hot weather, it is often the case that the HiveOS control interface does not detect substantial operational data on a fixed number of machines. (This part is a personal guess)
Although the REBOOT order will have short-term improvements after rebooting, it will soon happen again.
This is a problem that is being resolved after using HiveOS.
As long as the HiveOS control interface is not detected, the real-time data return on the mine pool web page will start to decline. I do not know what the relationship between the two is what is being considered.
I noticed that when Claymore was in operation, the command that would control the balance of power to calculate the temperature seemed to be -ttli. I wonder if there is any way to adjust it from the part…?
I am not familiar with the program part.
Also need to slowly think about solutions…
P.S: This is a GOOGLE translation. If you feel strange grammar, please forgive me.
During this time, although the operation of the machine has stabilized.
But from time to time, there will still be machines:
Claymore Reboot: WATCHDOG: GPU error, you need to restart miner :(.
Is this simply because the overclocking setting is too high?
The reason for this doubt is that my overclocking has slowly been fine-tuning recently, but the same overclocking is set on different machines. Some of them can adapt to higher settings, but some are not.
(I know that every machine operates is not exactly the same)
Continuously observe the operation of the machine every day
P.S: This is a GOOGLE translation. If you feel strange grammar, please forgive me.
я выставил разгон 1200 вместо 1600. работает всё отлично… раз в день отваливается, но причина какая-то другая.
1600 на windows работает без проблем. на линуксе процесс ethminer грузит процессор на 105%. при разгоне +1200 - процесс ethminer ведет себя прилично.
оставил 1200 и забыл о проблеме…
у товарища всегда стоит gen2. и у меня тоже стоит gen2. это в наших случаях не помогает.
I am still experiencing this exact issue and have tried all the suggestions here to no avail. Is there another thread or resolution from @HIVE on this?
у меня стоял разгон 1500-1600.
была загрузка процессора 5.
убавил разгон до 1000.
стало всё отлично! (кроме хешрейта)
на днях вернул 1500. сейчас тоже всё отлично.
не представляю в чем причина… (рекомендую направить дополнительные кулеры на заднюю стенку видеокарт)