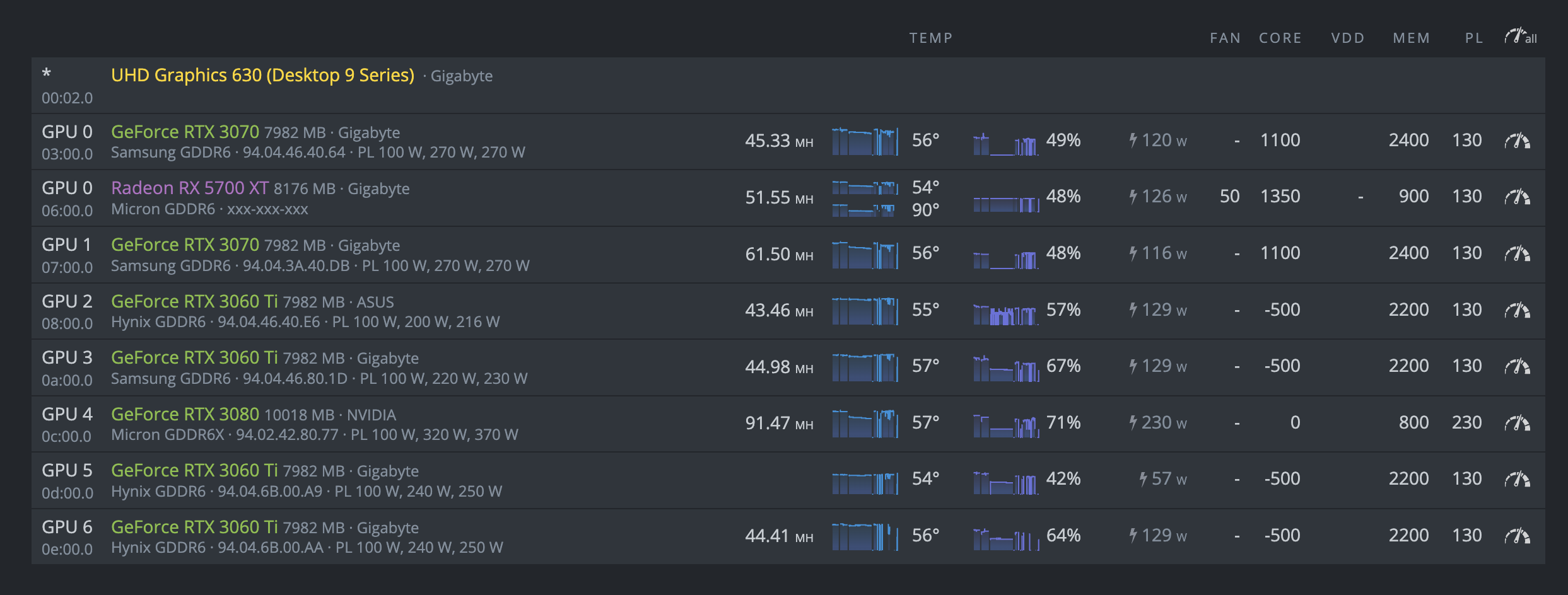
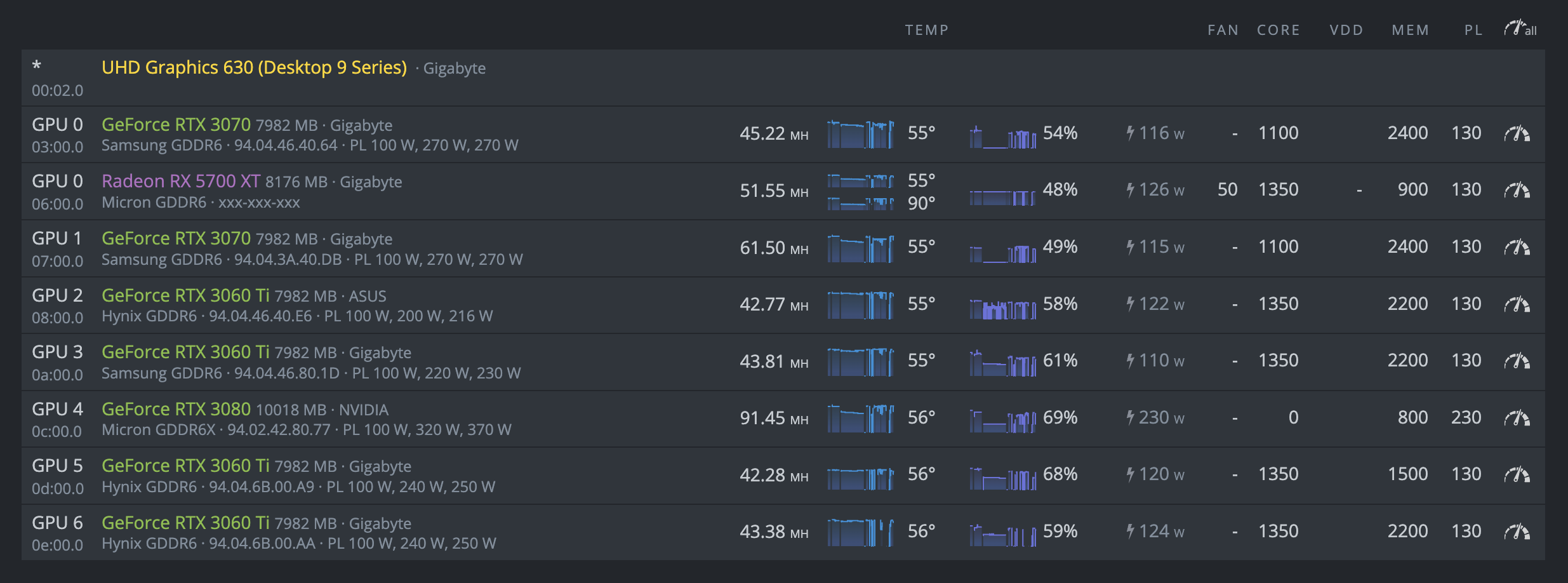
For the past 3 months up until last Friday, everything has been working swimmingly. As of this weekend however, I can’t get the rig to be stable. It will last anywhere from 2 minutes to 4 hours, but always ends up the same.
![]()
I’ve been dual mining ETH + ALPH, but currently trying to get it working just on ETH.
Here’s what I’ve tried so far:
- Stopped dual mining ALPH
- Decreased/removed overclocks
- Flashed fresh copy of HiveOS
- Removed a couple of GPUs (more on that below)
- Updated to latest drivers
Right when this error pops up, the last 2 GPUs in my list stop reporting hashrate. This is even reflected in the console. I attempted disconnecting both of those cards and I was able to mine without issue for 1+ hours.
Next I plugged one in and left the other out, and again was able to achieve stable mining. I thought for sure the card still unplugged was just toasted, but I decided to plug that one back in and remove the other. Stable mining.
At this point I’m not sure what the issue could be. One other thing that I’ve been noticing is that occasionally I will get “DAG verification failed” notice when first starting the mining software. If anyone has any ideas or suggestions, I am all ears. Rig info below:
- 4x 3060ti (2 problem cards included)
- 2x 3070
- 1x 5700 XT
- 1x 3080
- 2x 1000W EVGA PSU