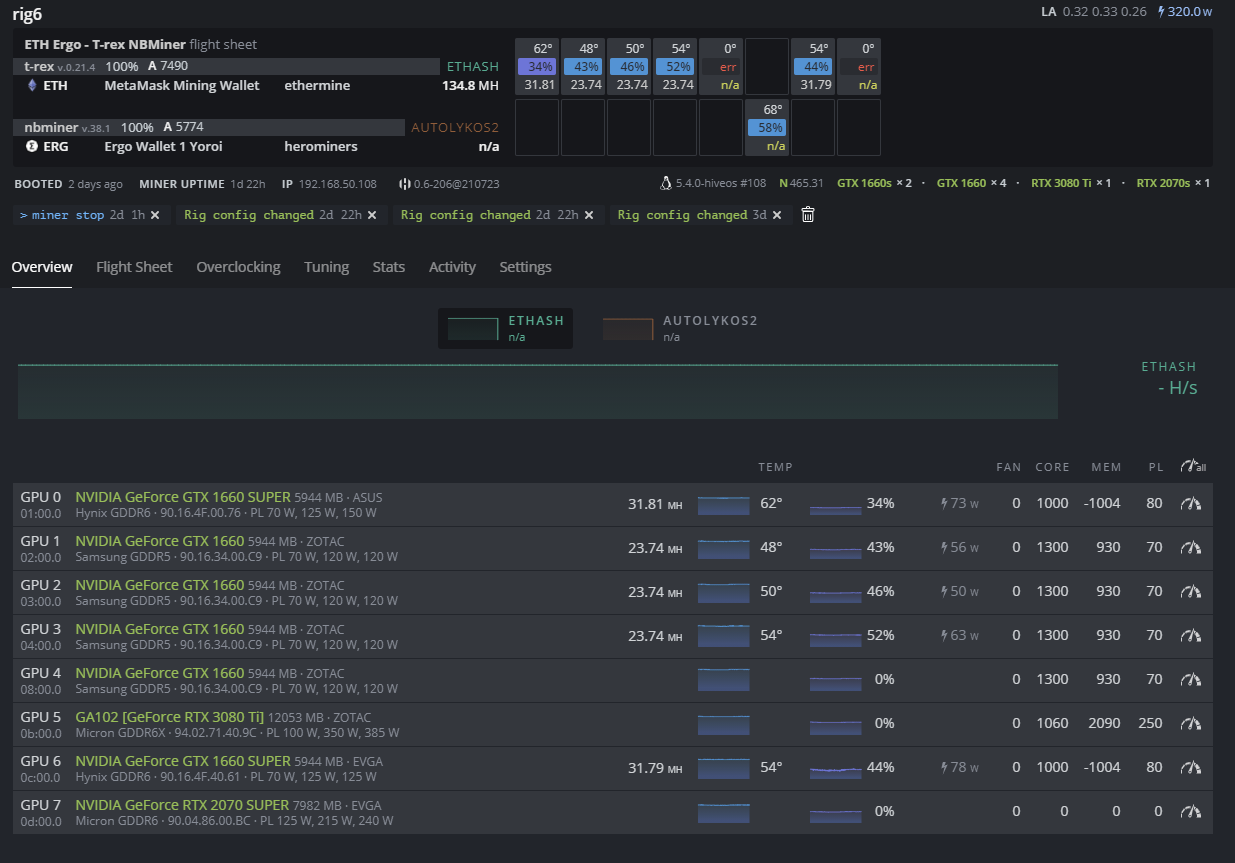
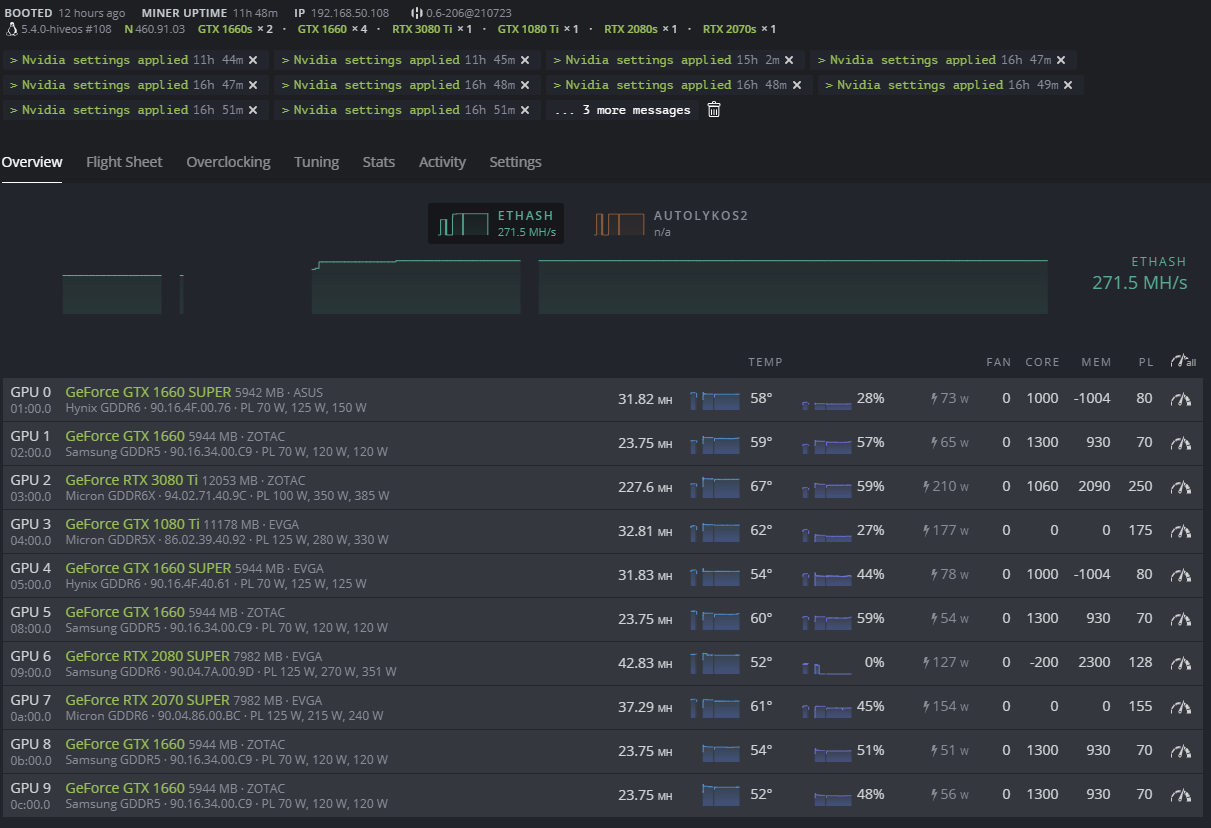
Piggybacking on your post (hope that’s ok).
I am getting similar errors and same symptoms (GPU suddenly stops showing watts, then temps disappear, then GPUs go offline). It happens about 2-4 hours after restarting. I thought it was the 2070S, but this morning, the 3080Ti (mining ERG) started acting up.
Any help would be awesome.
Things I have tried:
- restarting
- updating nvidia drivers
- updating BIOS
- setting all PCIe to Gen2
- changing miners
- taking out GPUs to reduce load
- switching around risers
- no OC
Jul 30 11:47:35 rig6 kernel: [ 141.317947][T10582] NVRM: Xid (PCI:0000:0d:00): 43, pid=10537, Ch 00000010
Jul 30 11:48:18 rig6 kernel: [ 184.310406][ T1060] NVRM: Xid (PCI:0000:0d:00): 13, pid=16136, Graphics SM Warp Exception on (GPC 4, TPC 3, SM 1): Out Of Range Address
Jul 30 11:48:18 rig6 kernel: [ 184.310442][ T1060] NVRM: Xid (PCI:0000:0d:00): 13, pid=16136, Graphics Exception: ESR 0x525fb0=0xc03000e 0x525fb4=0x20 0x525fa8=0x4c1eb72 0x525fac=0x174
Jul 30 11:48:18 rig6 kernel: [ 184.324545][T16180] NVRM: Xid (PCI:0000:0d:00): 43, pid=16136, Ch 00000010
Jul 30 11:48:59 rig6 kernel: [ 225.380030][ T4498] NVRM: Xid (PCI:0000:0d:00): 31, pid=21000, Ch 00000013, intr 00000000. MMU Fault: ENGINE HOST0 HUBCLIENT_HOST faulted @ 0x6_222c8000. Fault is of type FAULT_PDE ACCESS_TYPE_VIRT_READ
Jul 30 11:49:05 rig6 kernel: [ 231.191075][ T1060] NVRM: Xid (PCI:0000:0d:00): 31, pid=953, Ch 00000000, intr 00000000. MMU Fault: ENGINE HOST9 HUBCLIENT_HOST faulted @ 0x1_00060000. Fault is of type FAULT_PDE ACCESS_TYPE_VIRT_READ
Jul 30 11:49:12 rig6 kernel: [ 238.577707][ C0] NVRM: Xid (PCI:0000:0d:00): 8, pid=2356, Channel 00000008