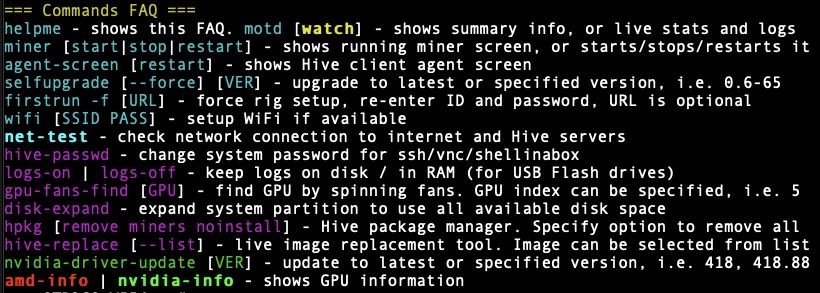
Thank you. Youve been the most helpful so far. For updating the kernel is there a way I can do that from the terminal or do I have to force a reflash of the usb?
Edit: I have found the command to update version and kernel, I am now on version 110.
I can look into using an nvme / m.2 drive as I have a few spare but theyre all 512GB or 1TB and that feels like it would be a waste. I can look into getting 128GB nvme ssds though. However, you would be correct that this board has no nvme slot. (ver 1.1 does but 1.0 and 1.2 do not.) I have been running USB on all of my rigs with only one instance ( and already older usb ) dying after a power outage. I can look into using a standard SATA SSD as I do have a few 128 or 256 GB instances laying around but I havent used those as they cost more power than a USB.
I can easily run disk expand. Where can I enable logging?
I’ll look more into rebtech and hold off for now then. I’ll also look into a TB 360 Pro 2 or H110. Is there anywhere specific you recommend I get one of those boards from? Do these boards all have a limitation of Nvidia GPUs needing to be only the first 6-8 slots? I recall seeing some blueprints showing that PCIe slots 6-11 do not fully fupport nvidia gpus on the btc b250 pcie version.
I wanted to downsize rig amount to mitigate both HiveOS and electrical costs but I’ve also seen more information about people sticking to 6-8 GPU systems and eating the costs for general stability.
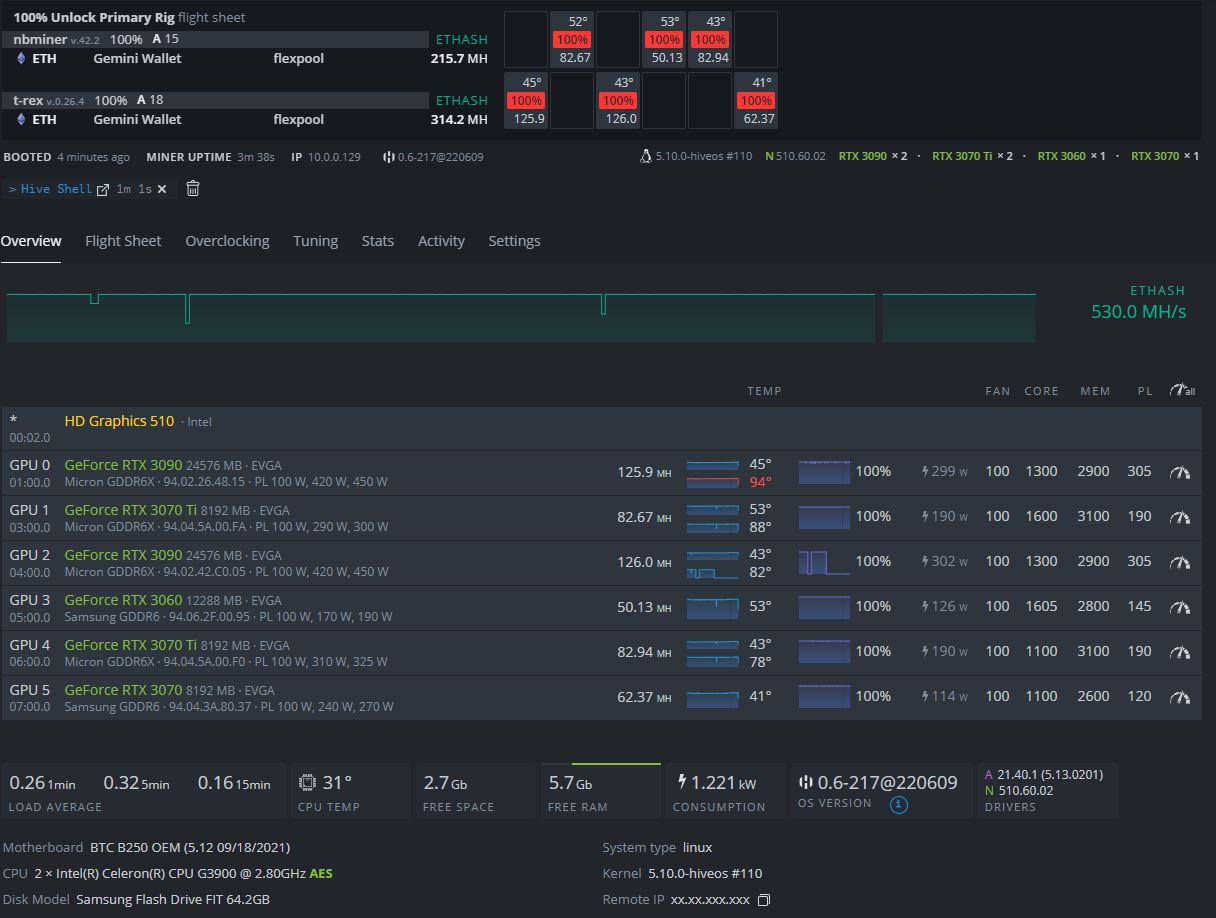
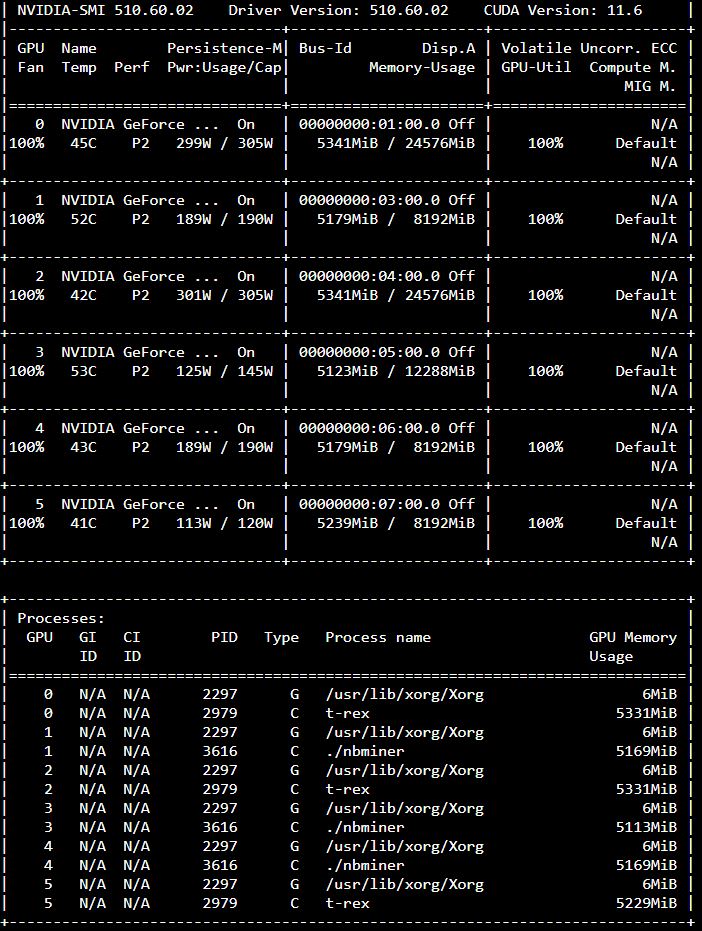
I’ll post another update after another 48-72 hours have passed since these changes or whenever the next post occurs.