I’ll try to stick to the facts and make this simple. I have spent probably 20 hours troubleshooting at this point including rebuilding the whole rack.
Since Feb, I’ve had a 12 GPU (all 3070 and 3060Ti) running very stable on HiveOS.
I am using 2x HP server PSUs and Parallel Miner X11 and ZSX card
A couple of weeks ago I noticed 7 cards kept dropping off. Reboots weren’t helping so I went into the basement to troubleshoot. While troubleshooting, the ZSX caught on fire! I got things back up pulling a PSU and ZSX from another rig that I’d recently shut down. Everything came back up fine.
But because I was concerned about the power draw on each PSU, I ordered a 3rd PSU and another ZSX card to spread the load out.
Upon installing the 3rd PSU, I kept having 7 cards drop offline again after a few minutes. Ultimately I ended up rebuilding the whole rig as I couldn’t be sure that risers and GPUs were connected to the same PSU. I made sure when I booted that the 1x PCIe slot LED on the MB came on for each GPU (in some cases I had to replace risers to get it to come on, risers that were just working the day before… replaced 3 sets I think).
I have still having the same issue, 7 cards drop off after a few minutes (they are on multiple PSUs). Example error from syslog:
Jul 1 13:03:43 RAWBAR-RIG1 kernel: [ 447.812938][ C0] NVRM: GPU at PCI:0000:05:00: GPU-258fe041-3674-470b-c91b-b37c750329db
Jul 1 13:03:43 RAWBAR-RIG1 kernel: [ 447.812943][ C0] NVRM: GPU Board Serial Number:
Jul 1 13:03:43 RAWBAR-RIG1 kernel: [ 447.812948][ C0] NVRM: Xid (PCI:0000:05:00): 79, pid=0, GPU has fallen off the bus.
Jul 1 13:03:43 RAWBAR-RIG1 kernel: [ 447.812957][ C0] NVRM: GPU 0000:05:00.0: GPU has fallen off the bus.
Jul 1 13:03:43 RAWBAR-RIG1 kernel: [ 447.812960][ C0] NVRM: GPU 0000:05:00.0: GPU is on Board .
Now, If i power off the 3rd PSU, 8 cards come up and mine fine, no issues at all. I tested for 24 hours.
If I turn on that 3rd PSU (which is a brand new PSU and brand new ZSX), which has 4 cards connected to it, I have 7 cards drop off the system and vanish as far as HiveOS is concerned…
Nothing in the t-rex.log of substance.
-----------------20210701 13:03:49 -----------------
Mining at eth-us-east.flexpool.io:4444, diff: 4.00 G
GPU # 0: EVGA RTX 3070 - 52.05 MH/s, [T:51C, P:119W, F:59%, E:437kH/W], 6/6 R:0%
GPU # 1: EVGA RTX 3070 - 52.05 MH/s, [T:67C, P:119W, F:67%, E:437kH/W], 5/5 R:0%
GPU # 2: EVGA RTX 3060 Ti - 51.73 MH/s, 4/4 R:0%
GPU # 3: Zotac RTX 3060 Ti - 52.20 MH/s, 3/3 R:0%
GPU # 4: Gigabyte RTX 3070 - 51.94 MH/s, 4/4 R:0%
GPU # 5: Gigabyte RTX 3070 - 52.06 MH/s, 6/6 R:0%
GPU # 6: Gigabyte RTX 3070 - 51.94 MH/s, 10/10 R:0%
GPU # 7: RTX 3060 Ti - 51.88 MH/s, 2/2 R:0%
GPU # 8: EVGA RTX 3070 - 51.94 MH/s, 6/6 R:0%
GPU # 9: ASUS RTX 3070 - 52.05 MH/s, [T:61C, P:119W, F:66%, E:437kH/W], 6/6 R:0%
GPU #10: Gigabyte RTX 3070 - 52.05 MH/s, [T:60C, P:123W, F:68%, E:423kH/W], 8/8 R:0%
GPU #11: ASUS RTX 3070 - 52.05 MH/s, [T:59C, P:119W, F:62%, E:437kH/W], 7/7 R:0%
Hashrate: 623.94 MH/s, Shares/min: 11.704 (Avr. 10.691)
Uptime: 6 mins 21 secs | Algo: ethash | T-Rex v0.20.4
20210701 13:03:58 ethash epoch: 424, block: 12743028, diff: 4.00 G
20210701 13:04:06 [ OK ] 68/68 - 623.93 MH/s, 26ms … GPU #0
20210701 13:04:06 [ OK ] 69/69 - 623.93 MH/s, 24ms … GPU #9
20210701 13:04:07 [ OK ] 70/70 - 623.93 MH/s, 22ms … GPU #9
20210701 13:04:17 ethash epoch: 424, block: 12743029, diff: 4.00 G
-----------------20210701 13:04:19 -----------------
Mining at eth-us-east.flexpool.io:4444, diff: 4.00 G
GPU # 0: EVGA RTX 3070 - 52.05 MH/s, [T:51C, P:119W, F:59%, E:437kH/W], 7/7 R:0%
GPU # 1: EVGA RTX 3070 - 52.05 MH/s, [T:67C, P:119W, F:67%, E:437kH/W], 5/5 R:0%
GPU # 2: EVGA RTX 3060 Ti - 0.00 H/s, 4/4 R:0%
GPU # 3: Zotac RTX 3060 Ti - 0.00 H/s, 3/3 R:0%
GPU # 4: Gigabyte RTX 3070 - 0.00 H/s, 4/4 R:0%
GPU # 5: Gigabyte RTX 3070 - 0.00 H/s, 6/6 R:0%
GPU # 6: Gigabyte RTX 3070 - 0.00 H/s, 10/10 R:0%
GPU # 7: RTX 3060 Ti - 0.00 H/s, 2/2 R:0%
GPU # 8: EVGA RTX 3070 - 0.00 H/s, 6/6 R:0%
GPU # 9: ASUS RTX 3070 - 52.05 MH/s, [T:61C, P:119W, F:67%, E:437kH/W], 8/8 R:0%
GPU #10: Gigabyte RTX 3070 - 52.05 MH/s, [T:61C, P:125W, F:68%, E:420kH/W], 8/8 R:0%
GPU #11: ASUS RTX 3070 - 52.05 MH/s, [T:59C, P:119W, F:63%, E:437kH/W], 7/7 R:0%
Hashrate: 260.24 MH/s, Shares/min: 11.478 (Avr. 10.526)
Uptime: 6 mins 51 secs | Algo: ethash | T-Rex v0.20.4
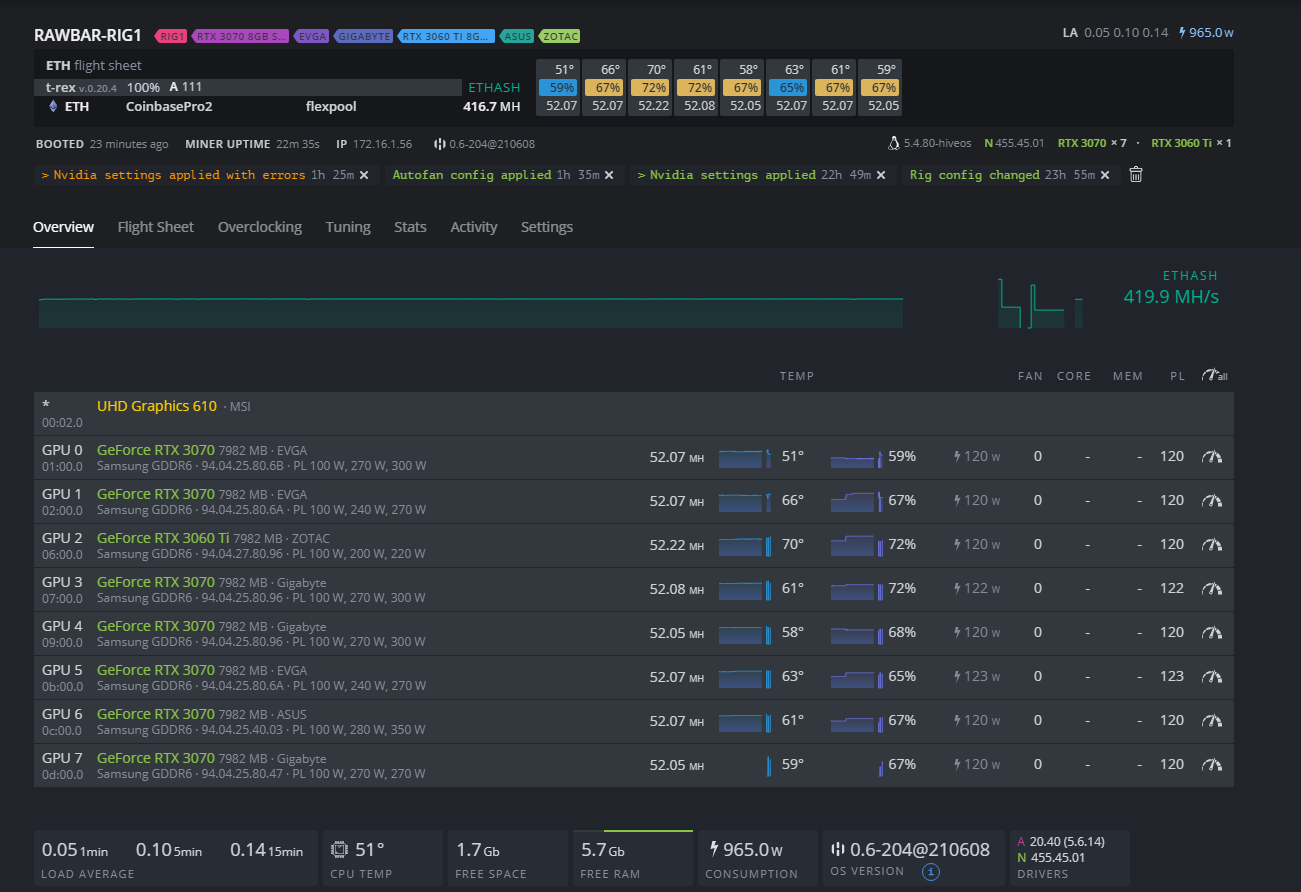
Cards are currently NOT overclocked. I’ve only set the voltage max so as not to overload the PSUs.
Yesterday I did see an error that I’m not seeing today that preceded the 7 cards dropping off. It related to the NVRM nvidia tool reporting that it couldn’t read the temperature of card #2. Followed by 7 cards immediately falling off the bus. I disconnected #2, rebooted, but same problems happened to the other 6 cards.
Note: These screenshots are from yesterday when I still had some OC applied.


This is just so strange. I have spent so much time on this I really need another set of eyes. The fact I’m losing 7 cards across multiple PSUs with 3 PSUs connected, but not losing any cards if I shut off the one new PSU doesn’t make any sense to me.
I looked at the Motherboard bios config as well. That’s an H310-F Pro w/8GB memory. I didn’t see anything wrong that jumped out at me.