



Please tell me how you can fix this error?
1 Like
It should be added that the minimum system requirements are 64 bit ubuntu 18.04
Is there any plans to make this work for Nvidia no updates to public repo in 14 months… ? Looks like the issue is with the hiveos kernel…
ERROR: Failed to run `/usr/sbin/dkms build -m nvidia -v 460.39 -k 4.15.18-hiveos`: Error! Your kernel headers for kernel 4.15.18-hiveos cannot be found.
Based on latest Hive Stable Image
- Linux kernel 5.4.99-hiveos
- Linux amdgpu kernel module with support GPU up to “Big Navi”
- AMD OpenCL 20.40
- Nvidia support added (but not tested very well)
Installation steps without changes
I had to run following command to allow miner to find AMD cards:
echo /opt/amdgpu-pro/lib/x86_64-linux-gnu >> /etc/ld.so.conf && ldconfig
Also I think it would be better to use ipxe instead of legacy boot. It works way better for me.
Two things I came across while trying to get this running:
If you get the following error while running the command in the OP:
pxe-setup.sh: line 54: /tmp/pxe-server/hiveos-pxe-diskless-master/pxeserer/hiveramfs/hiveramfs.tar.xz: No such file or directory
Then you are missing the ‘unzip’ command which does not ship with the latest Ubuntu Server LTS. Installing it via apt fixed the issue for me.
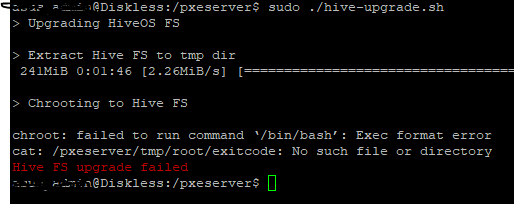
Second, if you are running this in a VM like VirtualBox, in order to use the hive-upgrade.sh, you have to add two lines to the file at line 89:
mv ./etc/resolv.conf{,.bak}
cp /etc/resolv.conf ./etc/resolv.conf
If not, you’ll get errors when the script runs that it’s unable to resolve any domains and the server will never actually pull updates.
W: Failed to fetch http://archive.ubuntu.com/ubuntu/dists/bionic/InRelease Temporary failure resolving ‘archive.ubuntu.com’
1 Like
I’ve created small script which makes hiveos image usable, does small clean up and improves security.: HiveOS fix - Pastebin.com
Maybe it will be useful for others too.
1 Like
Even AMD GPUs won’t work without fixing the image. So just create your image and it will work, setup tftp with ipxe on it, add it into your dhcp server and setup any http server to load boot config and other files. It will work with any linux.
1 Like
Hello everyone, I want to report a serious bug. The diskless installation of hiveos is problematic. I have
tested it many times in the last few days and installed it according to the latest tutorial. After the client
gets the ip, there will be a tftp error and the startup file cannot be found. But according to an old video
client of youtube, it can be started normally without a disk. Although it can connect to the hiveose server
after startup, the client cannot load the nvidia graphics driver and cannot mine at all! ! !
Has hiveos strictly tested your diskless installation tutorial? Maybe there are very few who have diskless
demand like me! : ( 
AMD driver is still 18.40
Track changes here:
Any chance of booting from Network UEFI? Unfortunately some of my rigs only have Network UEFI boot. Was just curious if it was on the roadmap.
Hey Alpha,
I did not have the same problems as you, if you enable TFTP on the dnsmasq you need to disable the Atftpd service that is installed which is what is used for tftp. What version of ubuntu are you running? Here is my version: Ubuntu 18.04.5 LTS that seems to work well. The only change I needed to make was adding the resolv.conf. I am running this off of libvirt but I did also get it working on virtualbox.
The reason dnsmasq is not serving leases is because it is working as a proxy to your main dhcp server which is you router I presume which you can see in the config file located at: /etc/dnsmasq.conf
Also make sure your VM is in promiscuous mode for your network adapter on a bridged connection.
You can try a sudo netstat -nap | grep 69 to see what program is currently running on port 69 and see if you can stop it or if it’s a service you need.
Check out the atftpd config, is it pointing to the right directory? cat /etc/default/atftpd should tell you near the end of the file.
What miners have been tested with the Nvidia drivers? I have been able to mine ubiq with phoenixminer but not able to mine RVN with NBMiner. Below is the error in the miner log file.
[14:41:44] ERROR - CUDA Error: PTX JIT compiler library not found (err_no=221)
[14:41:44] ERROR - Device 8 exception, exit …
[14:41:44] ERROR - CUDA Error: PTX JIT compiler library not found (err_no=221)
[14:41:44] ERROR - Device 11 exception, exit …
free(): corrupted unsorted chunks
[14:41:45] ERROR - !!!
[14:41:45] ERROR - Mining program unexpected exit.
[14:41:45] ERROR - Code: 11, Reason: Process crashed
[14:41:45] ERROR - Restart miner after 10 secs …
[14:41:45] ERROR - !!!
I was able to get past this error by installing the nvidia-cuda-toolkit to the image.
apt install nvidia-cuda-toolkit -y
Is there anyway to enable Nvidia with PXE? We have around 600 rigs that use Nvidia cards (mostly p106) and we want to move to net boot for stablity.
1 Like
Current version appears to have an issue booting out of the box… seems to be an issue in initrd-ram.img:/scripts/nfs where $fs_size is calculated and passed in the pipe to ps on line 73 & 74.
I’m currently testing 100% virtual before I roll this out to a production rig for testing - I see the client pull the file from the nginx server but it fails with an error.
Download and extract FS to RAM
pve: option requires an argument – ‘s’
Try `pv --help’ for more information.
xz: (stdin): File format not recognized
tar: Child returned status 1
tar: Error is not recoverable: exiting now
Which then results in a cascade of failures on boot. I never see the client request the tar.xz file from the nginx daemon according to logs.
I’ve tried fixing the error by unpacking the initrd-ram.img file, editing the file, and repacking. I’m new to PXE and manipulating the initrd image so I may not be packaging the .img file correctly seem to indicate the img is not being extracted properly by the client.
Any pointers would be much appreciated.
UPDATE and SOLVED:
I managed to solve the issue. It was definitely a problem on my end dealing with virutalization. I realize this is a fringe case as I am using a virtualized client for testing and won’t be using virtualized clients for production but I’m going to post my causality anyway in case anyone else is running into this issue.
I’ve managed to get the image file repacked properly. For anyone wondering how to do that the command I used which appears to work is: find . | cpio -H newc -o | gzip -9 > ~/initrd-ram.img
The issue appears to be with line 73 in /scripts/nfs which is:
fs_size=$(/bin/wget --spider ${httproot}${hive_fs_arch} 2>&1 | grep “Length” | awk ‘{print $2}’)
Debugging I tried to echo the value of fs_size which returned a null value… so the above is defunct likely due to some output format changing from wget. So I threw in a few debug commands surrounding line 73 to show the output of /bin/wget --help and /bin/ip link…
It turns out that the initrd image wasn’t able to load the driver for the virtIO network interface emulated by proxmox… so switching the VM’s network interface card model to Intel E1000 fixed the issue.
А как-то можно обновить сервер на определенную версию именно образ системы? чтоб не последний а который нужно
1 Like