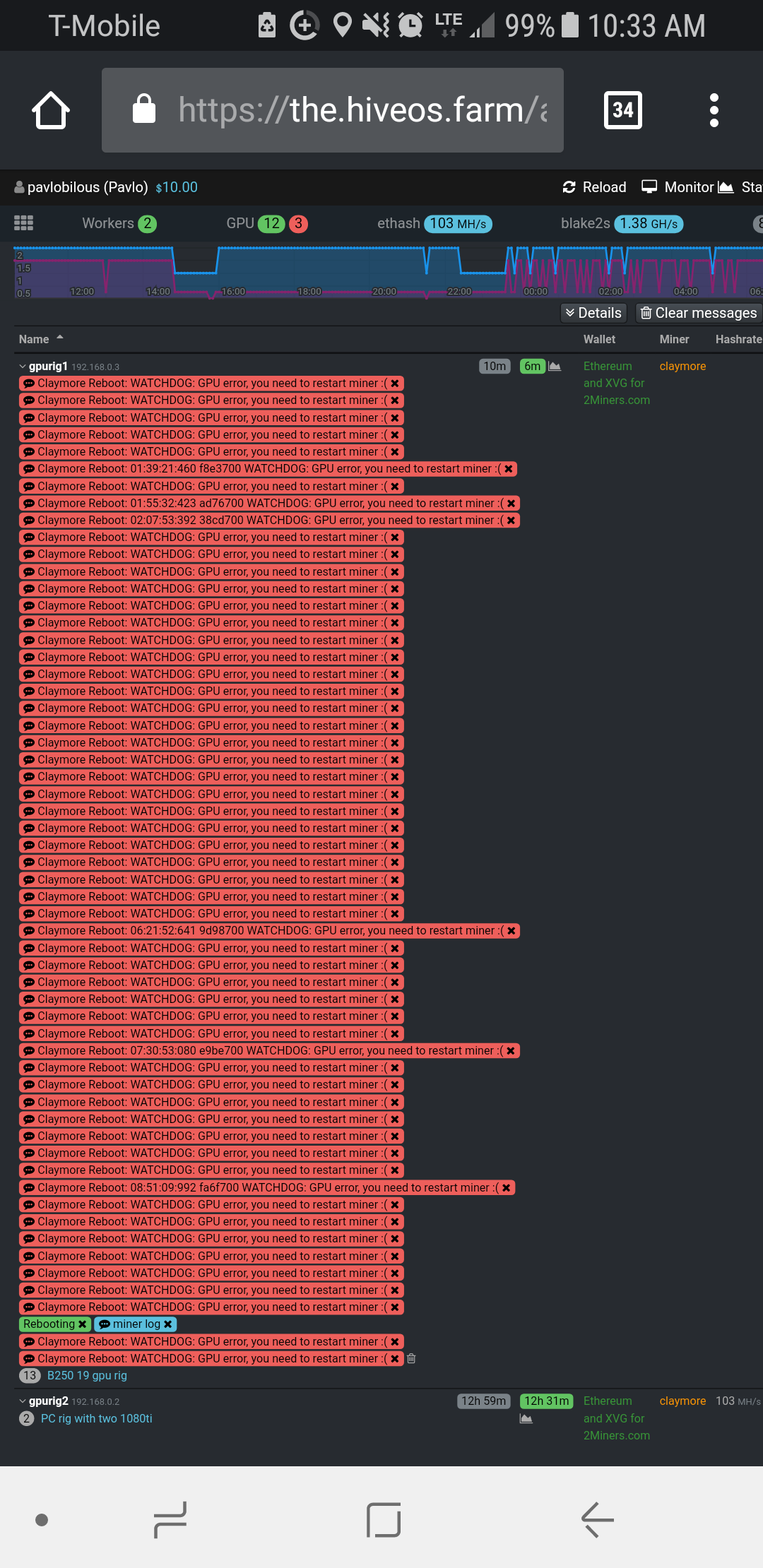
So after extensive testing, the riser and GPU in question were not defective at all. What actually resolved the issue was reducing the GPU quantity from 12 to 10 in that particular rig. I came to that realization/conclusion yesterday when I re-installed the riser and GPU and the error messages re-appeared, then, again, I removed a riser and GPU, and the error messages stopped.
This particular rig used to function properly with 12 GPUs. However, that may have been on Windows, before I switched the rigs over to Hive OS.
For clarification, my other rig that also produced these error messages has only 6 GPUs. So the 11+ GPU issue doesn’t apply in every situation.